Top Interview Questions for DS
In this article, we’ll explore the top questions commonly asked in data science interviews, breaking them down into simple, easy-to-understand explanations.
Q.1 Explain the bias-variance tradeoff.


Bias and variance are inversely proportional to each other. When bias increases variance decreases. Therefore, we need to find a balance trade between the two.
Q2. What is overfitting, and how can you prevent it?
Overfitting is a common problem in machine learning where a model learns the training data too well, capturing not only the underlying patterns but also the noise and random fluctuations. This makes the model highly complex and tailored to the specific data it was trained on, resulting in excellent performance on the training set but poor generalisation to new, unseen data.
Key Characteristics of Overfitting:
- High Training Accuracy, Low Test Accuracy: The model performs exceptionally well on the training data but fails to perform adequately on the test or validation data.
- Complexity: The model has learned to fit even the minor details and noise in the training data, which does not represent the underlying distribution of the data.
- High Variance: The model’s predictions vary greatly with small changes in the training data, making it sensitive to outliers
How to Prevent Overfitting:
1. Regularisation.
2. Cross-Validation.
3. Early Stopping.
4. Increasing training data (data augmentation).
5. Pruning.
6. Using ensemble technique model like RF, XG boost.
Q3. Explain Regularisation.
It is a technique used in M.L to prevent overfitting by adding a penalty term to the loss function that model optimises. This term penalise large coefficient encouraging the model to keep the coefficient small and simple.
Use lasso regularisation when there is high dimensional data & not all features are important. Those input features which are not very important can be ignore because in lasso regularisation coefficient become 0.
Use Ridge regularisation when all the features are important because coefficient value doesn’t become exactly 0 in case of ridge regularisation.


When value of coefficient is less then bias decreases (model will overfit) and variance increases whereas when the value of coefficient is high bias increases (model will under-fit) and variance decreases.

L1 norm is absolute/mode value.
L2 norm is square value.
Q4. What is the curse of dimensionality? What .are the ways to mitigated it?
It refers to the various challenges and problems that arise when analysing and organising data in high-dimensional spaces. As the number of dimensions (features or variables) increases, the volume of the space increases exponentially, leading to several issues:
1. Increased Computational Complexity.
2. Overfitting.
3. Sparse Data: When data is sparse becomes difficult to find meaningful patterns or relationships, as the data points are far apart from each other.
Methods to mitigate curse of dimensionality:
1. Feature Selection by various statistical and regularisation technique.
2. Dimensionality Reduction technique like PCA, t-SNE etc.
3. Increasing training data.
4. Use Algorithms Designed for High-Dimensional Data like RF, XG Boost, GBDT.
Q5. What is PCA?
Principal component analysis is a dimensionality reduction technique used in M.L to transform a large set of variables into a smaller set such that it contains most of the information from the original dataset or you can say that while retaining as much variance (spread) as possible. This can help in simplifying the dataset speeding up algorithms.
It works by identifying the directions (principal components) along which the variance of the data is maximised. These directions are orthogonal (perpendicular) to each other and ordered by the amount of variance they explain in the given data.

Steps involved in PCA:
1. Standardise the data.
2. Compute the covariance matrix.
3. Calculate eigen vectors and eigen values of the covariance matrix to identify the principal components.
4. Choose top k components that explain the most variance.
5. Project the data onto these selected principal components to obtain a lower dimension representation.
Eigen Vectors: These are the directions of the new coordinate system where the data varies the most, in simple words where it explained the maximum variance.
Eigen Values: These are the magnitude from the eigen vector which capture the most variance.
Q6. How to handle imbalance dataset?
An imbalanced dataset is one where the classes are not represented equally. This is common in scenarios like fraud detection, medical diagnosis, spam filtering where the no of positive cases is significantly lower than no. of negative cases.
This imbalance can lead to biased models that perform well on majority class but poorly on minority class.

The main challenge with imbalanced datasets is that most M.L algorithms assume an equal distribution of classes and thus can be biased towards majority class, leading to poor predictive performance on the minority class.
Metrics like accuracy can be misleading in these cases. Instead of accuracy metrics it is better to use precision, recall or F1 score metrics depending on the problem statement to decide the model’s performance.

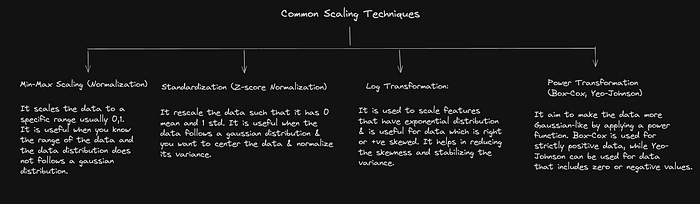
Q7. What is scaling and explain various scaling techniques?
Scaling refers to the process of adjusting the range of feature values in your dataset so that they are on a comparable scale. This is often necessary in machine learning because many algorithms are sensitive to the scale of the input data. It is often necessary in M.L to ensure that different features contribute equally to the model.
Why Scaling is Important:
- Equal contribution of the features: Features with larger scales can dominate distance-based models (like k-Nearest Neighbors, SVMs, or clustering) or optimization algorithms. Standardization ensures that all features contribute equally to the model by bringing them to the same scale.
- Improved Convergence in Gradient-Based Methods: Algorithms like gradient descent converge faster when the features are on a similar scale. This is because the gradients are more balanced, avoiding situations where some weights update much faster than others.
- Better Model Performance: Many algorithms, especially those based on distance metrics (e.g., KNN, clustering algorithms), perform better when features are scaled. If features have different units or vastly different ranges, it can distort the calculations of distances or angles between data points.
- Prevention of Feature Dominance: In algorithms that do not inherently handle feature scaling, like linear regression, features with larger ranges can dominate the model and skew the results, leading to biased models.
Type of scaling techniques:
Q8. How to handle missing values for different data type (categorical, numerical and time series)?
Handling missing values in data preprocessing is a crucial step because missing data can lead to biased estimates, reduce the representativeness of the sample and ultimately affect the model performance.

Q9. How to handling outliers in a dataset?
Outliers are data points that significantly differ from majority of the data. They can be result of variability in the data, experimentally errors or measurement errors. Handling them is crucial because they can skew & mislead statistical analyses and ML models.


Weight base ML algorithms. like LR, DL, adaboost are highly effects by outliers whereas tree base algorithms. like DT, RF, XG boost does not effect much as compare to weight base algorithms.
For example: In house pricing dataset, extremely high prices might be outliers due to unique properties. Using box plot we could identify these outliers. Depending on the analysis goal, we might remove them if they result from the data entry errors or use log transformation to reduce their impact if they represent valid but extreme cases.
Q10. What is feature engineering?
F.E is the process of using domain knowledge to extract features from raw data that help M.L algorithms to capture patterns in a better way & improve their predictive performance. This involves creating, modifying or selecting features that make M.L models more effective.

Feature selection is also a technique of F.E. It involves choosing the most relevant features for the model. Techniques include statistical tests (like chi-square test, t-test, ANOVA test, etc.), correlation analysis (like spearman, heat map) & regularisation method like L1 lasso regularisation.
For example removing features that have low variance or high correlation with other features can simplify the model & improve performance (like removing features like no. of bedrooms and no. of bathrooms if total square feet area of the house is given for predicting house price).

Q11. Explain the concept of ensemble learning.
Ensemble learning is a technique in M.L where multiple models (base learners) are trained & combined to solve the same problem. The goal is to improve the overall performance, accuracy & robustness of the model by leveraging the strength of each individual model.


Most commonly used ensembling techniques are bagging and boosting. Both are used to improve the performance and robustness of the M.L models by combining multiple weak learners to create a strong learner.


Q12. What is the difference between cross validation and hyper parameter tuning?
Sometimes people get confused with two terminologies. However, both are different and play crucial role in the process of building and optimising machine learning models.

Q13. What is the difference between back-propagation and gradient descent?

In other words, back-propagation is an algorithms used to compute the gradients of the loss function w.r.t weights in NN, while G.D is an optimisation algorithms that uses these gradients to update the weights and minimise the loss function.

During the training of a neural network the steps are:
- Forward Pass : Input data is passed through the network to make predictions.
- Loss calculation : The loss function calculates the error by comparing predictions to actual targets.
- Backward Pass : The error is propagated backward through chain rule to compute the gradients of the loss w.r.t each weight.
- Weight Update (G.D) : These gradients are used to update the weights, aiming to minimise the loss function.
This process is repeated for many iterations (epochs) until the model converges to an optimal set of weights.
In short, G.D is one of the steps of backwards propagation that uses the gradient to update the weights, which aim to minimise the loss function.
Q14. What are metrics and explain different type of classification metrics.
Metrics are quantitative measure used to evaluate the performance of a M.L model. They help to determine how well a model is performing. They are crucial because they provide a standardised way to assess and compare models and helps in understanding how well a model is capturing the patterns in the data, guide the tuning of model parameters & help in ensuring that the model meets the desired performance criteria.

In M.L evaluating the performance of a classification model involves using various metrics that provide insights into different aspects of the model’s predictions. The most common metrics are accuracy, precision, recall and f1 score.

F1 score is the harmonic mean of precision & recall.
It is valuable when you need a balance between precision and recall, especially in scenraios with imbalanced classes. It is commonly used where both false positive and false negative matters.
In short, accuracy is useful for balanced datasets, precision for minimising false positive and recall for minimising false negative and f1 score for balancing precision and recall.
Confusion matrix
It is a table used to evaluate the performance of a classification model. It summarises the model’s predictions and shows the count of true positive, true negative, false positive and false negative.

F.P — no. of incorrectly positive predictions (type — I error)
F.N— no. of incorrectly negative predictions (type — II error)

A type I (false-positive) occurs if the investigator rejects a null hypothesis that is actually true whereas a type II error (false-negative) occurs if the investigator fails to reject a null hypothesis that is actually false.
Q15. Why is there a minus sign in gradient-based optimisation algorithms?
The minus sign is there in gradient descent because it helps to guide the model in the correct direction i.e. towards minimising the cost or loss function.
The gradient represents the direction of the steepest ascent, meaning it points towards the direction in which the loss function increases the most. So, if you move in the direction of gradient, the loss will increase.
However, in M.L problems, we aim to minimise the loss function. Therefore, we need to move in the opposite direction of the gradient, which is why we subtract the gradient when updating the parameters.
Q16. When to use Vanilla gradient descent, Mini Batch GD and Stochastic GD?

In industry, the order of usage of these algorithms is
Mini-Batch GD > Stochastic GD > Vanilla GD
Comparison Based on Computing Resources

