Text Summarisation using LSTM encoder and decoder architecture(beginner friendly)
Problem Statement
How company like in-shorts delivers news in less than 60 words?
- These companies used NLP algorithms which help in extracting the most relevant sentences from a longer text. These algorithms can identify key phrases and sentences that contain the essential information of the article.
- This technique involves selecting important sentences or phrases directly from the original text. Tools like TextRank or BERT can be used to rank the sentences and pick the most informative ones.
Since we are learning the basic, we will go with LSTM to train our model.
Reading the datasets
!gdown 1sui9RXxVsPDa4s2kooQwRGhb8taZhcgD
!gdown 1H3gdo7SLBiWE_GGD6_xcdAp2wJJFcd5Limport pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
summary = pd.read_csv("/content/news_summary.csv", encoding='iso-8859-1')
raw = pd.read_csv("/content/news_summary_more.csv", encoding='iso-8859-1')
summary.shape, raw.shapeDataset contain:
1. summary[“headlines”] feature contains the title for each news.
2. summary[“text”] column contains summary for the corresponding article.
3. sumaary[“ctext”] column contains the entire article written on the channel website.
For example:
- summary[‘headlines’]: ‘Daman & Diu revokes mandatory Rakshabandhan in offices order’,
“Malaika slams user who trolled her for ‘divorcing rich man’ “ - summary[‘text’] : ‘The Administration of Union Territory Daman and Diu has revoked its order that made it compulsory for women to tie rakhis to their male colleagues on the occasion of Rakshabandhan on August 7. The administration was forced to withdraw the decision within 24 hours of issuing the circular after it received flak from employees and was slammed on social media.’,
‘Malaika Arora slammed an Instagram user who trolled her for “divorcing a rich man” and “having fun with the alimony”. “Her life now is all about wearing short clothes, going to gym or salon, enjoying vacation[s],” the user commented. Malaika responded, “You certainly got to get your damn facts right before spewing sh*t on me…when you know nothing about me.”’
For raw dataset:
This dataset is similar to summary dataset.
- raw[“headlines”] feature contains the title for each news.
- raw[“text”] column contains summary for the corresponding article.
Concatenating both the datasets
# Concatenate the summary and the raw files
df = pd.concat([raw, summary]).reset_index(drop=True) #vertical concatnationSince we are building a basic encoder-decoder model using LSTM, we limit the text summaries to a range of 40 to 60 words. Therefore, we are removing rows where the number of words does not fall between 40 and 60.
config = {'min_text_len':40,
'max_text_len':60,
'max_summary_len':30,
'latent_dim' : 300,
'embedding_dim' : 200}
print(f'Before filtering: {raw.shape}')
df = df.loc[((df['text'].str.split(" ").str.len()>config['min_text_len'])
&(df['text'].str.split(" ").str.len()<config['max_text_len']))].reset_index(drop=True)
print(f'After filtering: {df.shape}')A Sample row from the dataset
ran_num = np.random.randint(1, 10000)
print(f"Text: {df['text'][ran_num]}")
print()
print(f"Summary: {df['summary'][ran_num]}")
print()
print(f"Text length: {len(df['text'][ran_num].split())}")
print(f"Summary length: {len(df['summary'].str.split()[1])}")Output:
Text: A South Korean court on Friday sentenced former President Lee Myung-bak to 15 years in prison for corruption. He was found guilty of embezzlement, abuse of power and receiving illegal funds from Samsung Electronics in return for presidential pardon of its Chairman Lee Kun-hee. Myung-bak has denied any wrongdoing and claimed that the charges are politically motivated.
Summary: Ex-S Korea President Lee jailed for 15 years over corruption
Text length: 57
Summary length: 13
Why are we using LSTM architecture?
With simple RNN or vanilla RNN, we encounter a major drawback: vanishing and exploding gradients, which make it difficult to capture long-term dependencies.
What are Long-Term Dependencies?
With simple RNN or vanilla RNN, we encounter a major drawback: vanishing and exploding gradients, which make it difficult to capture long-term dependencies.
For example:
“I visited Paris last year during winter as a part of a business trip. For the first 2 days, I suffered from jet lag and stayed at a hotel near my office location. The weather was too cold for someone from a subcontinent. The trip lasted for 2 weeks, and I traveled by metro for most of my commute as the city is well connected. There were quite a lot of market areas for shopping to buy souvenirs too. During the weekend, I even got a chance to see the Eiffel Tower.”
In the above example, to predict the last words “Eiffel Tower,” the model needs to retain the information about the location “Paris” mentioned at the third word in the sentence. This ability to remember and utilize information from earlier in the sequence is called capturing long-term dependencies.
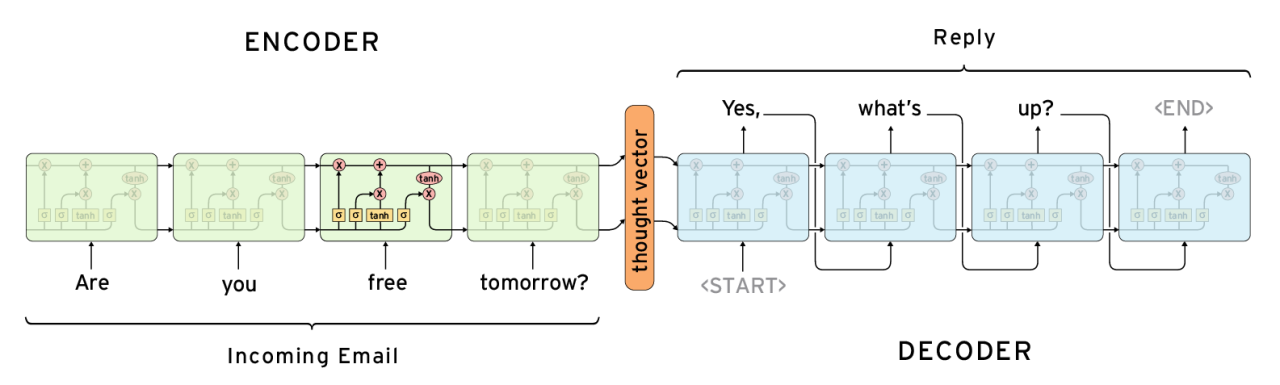
How does encoder decoder architecture works?
Let’s look at a diagram to see what’s inside the encoder-decoder model

Encoder Model
The encoder’s role is to process the input sequence and summarise the information into a context vector (also known as a thought vector). The encoder takes each element of the input sequence one at a time and updates its hidden state.
a) Input: A sequence of vectors (e.g., word embeddings of a sentence).
b) Output: A context vector that encapsulates information from the entire input sequence.
Workflow of encoder:
1. The encoder reads the input sequence one token at a time.
2. For each token, the encoder updates its hidden state.
3. After processing the entire input sequence, the final hidden state(s) of the encoder serve as the context vector.
Decoder Model
The decoder uses the context vector produced by the encoder to generate the output sequence. It generates the output sequence one token at a time, often with the help of the previous token generated by the decoder.
a) Input: The context vector from the encoder, and (during training) the previous target token.
b) Output: A sequence of vectors representing the predicted output sequence.
Workflow of decoder:
1. The decoder receives the context vector as its initial hidden state.
2. At each step, the decoder generates an output token and updates its hidden state.
3. This process continues until the entire output sequence is generated.
For Example
I like to travel and I visited Paris last year as a part of my business trip. It was winter season and too cold for someone from the sub-continent. I stayed at Hilton hotel and I was fortunate enough to get a room where from my window I could see the Eiffel tower.

Training an encoder-decoder model
import tensorflow as tf
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.layers import Embedding, LSTM, Dense, Input, InputLayer, TimeDistributed
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
from sklearn.model_selection import train_test_split
import string, reBasic code for textual data cleaning
# Remove non-alphabetic characters (Data Cleaning)
def text_strip(sentence):
sentence = re.sub("(\\t)", " ", str(sentence)).lower()
sentence = re.sub("(\\r)", " ", str(sentence)).lower()
sentence = re.sub("(\\n)", " ", str(sentence)).lower()
# Remove - if it occurs more than one time consecutively
sentence = re.sub("(--+)", " ", str(sentence)).lower()
# Remove . if it occurs more than one time consecutively
sentence = re.sub("(\.\.+)", " ", str(sentence)).lower()
# Remove the characters - <>()|&©ø"',;?~*! (special charcter)
sentence = re.sub(r"[<>()|&©ø\[\]\'\",;?~*!]", " ", str(sentence)).lower()
# Remove \x9* in text
sentence = re.sub(r"(\\x9\d)", " ", str(sentence)).lower()
# Replace CM# and CHG# to CM_NUM
sentence = re.sub("([cC][mM]\d+)|([cC][hH][gG]\d+)", "CM_NUM", str(sentence)).lower()
# Remove punctuations at the end of a word
sentence = re.sub("(\.\s+)", " ", str(sentence)).lower()
sentence = re.sub("(\-\s+)", " ", str(sentence)).lower()
sentence = re.sub("(\:\s+)", " ", str(sentence)).lower()
# Remove multiple spaces
sentence = re.sub("(\s+)", " ", str(sentence)).lower()
return sentencePreprocessing the “text” and “summary” column and introducing starting and ending tokens in “summary” column.
df['cleaned_text'] = df.text.apply(lambda x: text_strip(x))
df['cleaned_summary'] = df.summary.apply(lambda x: '_START_ '+ text_strip(x) + ' _END_')
df['cleaned_summary'] = df['cleaned_summary'].apply(lambda x: 'sostok ' + x + ' eostok')df = df[((df.cleaned_text.str.split().str.len()<=config['max_text_len']) &
(df.summary.str.split().str.len()<=(config['max_summary_len']+4)))].copy()
df = df.reset_index(drop=True)
print(df.shape)
#removing text & summary columns from the dataframe df and replacing them with cleaned_text and cleaned_summary respective
df = df.drop(['text', 'summary'], axis=1)
df = df.rename(columns = {'cleaned_text':'text',
'cleaned_summary':'summary'})Calculating % of words that come less than 5 times in the entire corpus
def get_rare_words(text_col):
# Prepare a tokenizer on testing data
text_tokenizer = Tokenizer()
text_tokenizer.fit_on_texts(list(text_col))
thresh = 5
cnt = 0
tot_cnt = 0
for key, value in text_tokenizer.word_counts.items():
tot_cnt = tot_cnt + 1
if value < thresh:
cnt = cnt + 1
print("% of rare words in vocabulary:",(cnt / tot_cnt) * 100)
return cnt, tot_cnt
x_train_cnt, x_train_tot_cnt = get_rare_words(text_col=X_train)
x_train_cnt, x_train_tot_cntThere are 64 % of words that are occuring less than 5 times in the entire corpus. We will remove these words because vocabulary size is very big and if these are words only 5 times that the model will not be able to learn anything.
Tokenise all the words
# Prepare a tokenizer, again -- by not considering the rare words
x_tokenizer = Tokenizer(num_words=x_train_tot_cnt - x_train_cnt)
# x_tokenizer = Tokenizer(num_words = x_train_tot_cnt)
x_tokenizer.fit_on_texts(list(X_train))
# Convert text sequences to integer sequences
x_tr_seq = x_tokenizer.texts_to_sequences(X_train)
x_val_seq = x_tokenizer.texts_to_sequences(X_test)
# Pad zero upto maximum length
x_tr = pad_sequences(x_tr_seq, maxlen=config['max_text_len'], padding='post')
x_val = pad_sequences(x_val_seq, maxlen=config['max_text_len'], padding='post')
# Size of vocabulary (+1 for padding token)
x_voc = x_tokenizer.num_words + 1
X_train[0]Input:
pakistani singer rahat fateh ali khan has denied receiving any notice from the enforcement directorate over allegedly smuggling foreign currency out of india it would have been better if the authorities would have served the notice first if any and then publicised this reads a press release issued on behalf of rahat the statement further called the allegation bizarre .
Output:
array([ 3, 106, 9, 29, 843, 434, 1253, 5, 863,
22, 1, 288, 5381, 853, 1223, 4, 464, 8,
12005, 15, 3360, 3, 3647, 90, 18, 11446, 6,
15980, 3, 653, 1231, 4, 24, 1, 46, 30,
156, 1, 105, 20, 12006, 18, 3820, 5920, 12,
11, 17, 488, 202, 1, 8957, 670, 2, 200,
1489, 5, 136, 19, 2301, 0]
Note : In “summary” column, 60 is the maximum length of the words. If there are say, 55 words then we are performing 0 post padding so that there should be equal no. of input at each time step.
Tokenising test side as well:
# Prepare a tokenizer, again -- by not considering the rare words
y_tokenizer = Tokenizer(num_words=y_train_tot_cnt - y_train_cnt)
# y_tokenizer = Tokenizer(num_words=y_train_tot_cnt)
y_tokenizer.fit_on_texts(list(y_train))
# Convert text sequences to integer sequences
y_tr_seq = y_tokenizer.texts_to_sequences(y_train)
y_val_seq = y_tokenizer.texts_to_sequences(y_test)
# Pad zero upto maximum length
y_tr = pad_sequences(y_tr_seq, maxlen=config['max_summary_len'], padding='post')
y_val = pad_sequences(y_val_seq, maxlen=config['max_summary_len'], padding='post')
# Size of vocabulary (+1 for padding token)
y_voc = y_tokenizer.num_words + 1Initialise LSTM Encoder and Decoder architecture
config = {'min_text_len':40,
'max_text_len':60,
'max_summary_len':30,
'latent_dim' : 300,
'embedding_dim' : 200}
latent_dim = config['latent_dim']
embedding_dim = config['embedding_dim']
max_text_len = config['max_text_len']
max_summary_len = config['max_summary_len']
x_voc = x_tokenizer.num_words + 1 # x_voc = 21033
# Encoder
encoder_inputs = Input(shape=(max_text_len, ))
# Embedding layer
enc_emb = Embedding(input_dim = x_voc, output_dim = embedding_dim,
trainable=True)(encoder_inputs)
# Encoder LSTM 1
encoder_lstm1 = LSTM(units = latent_dim, return_sequences=True,
return_state=True, dropout=0.4,
recurrent_dropout=0.4)
(encoder_output1, state_h1, state_c1) = encoder_lstm1(enc_emb)
# Encoder LSTM 2
encoder_lstm2 = LSTM(latent_dim, return_sequences=True,
return_state=True, dropout=0.4,
recurrent_dropout=0.4)
(encoder_output2, state_h2, state_c2) = encoder_lstm2(encoder_output1)
# Encoder LSTM 3
encoder_lstm3 = LSTM(latent_dim, return_state=True,
return_sequences=True, dropout=0.4,
recurrent_dropout=0.4)
(encoder_outputs, state_h, state_c) = encoder_lstm3(encoder_output2)
#encoder_outputs is not using anywhere in the further code. Why are we using this "encoder_outputs" then? Can't we put _ instead of encoder_outputs
# Set up the decoder, using encoder_states as the initial state
decoder_inputs = Input(shape=(None, )) #why None and why decoder recieved input externally. Dont it get input from the final output of encoder
# Embedding layer
dec_emb_layer = Embedding(y_voc, embedding_dim, trainable=True) #y_voc = 8726, using softmax the model with predict next word with highest probability.
dec_emb = dec_emb_layer(decoder_inputs) #input is coming from the encoder_outputs (last time step of encoder why are we giving input as decoder_inputs)
# Decoder LSTM
decoder_lstm = LSTM(latent_dim, return_sequences=True,
return_state=True, dropout=0.4,
recurrent_dropout=0.2)
(decoder_outputs, decoder_fwd_state, decoder_back_state) = decoder_lstm(dec_emb, initial_state=[state_h, state_c])
# what is decoder_fwd_state, decoder_back_state in the decoder architecture?
#maybe decoder_outputs: The full sequence of outputs from the LSTM layer for each time step.
#decoder_fwd_state: Typically the final hidden state (output) of the LSTM layer.
#decoder_back_state: Typically the final cell state of the LSTM layer.
# Dense layer
decoder_dense = TimeDistributed(Dense(y_voc, activation='softmax'))
decoder_outputs = decoder_dense(decoder_outputs)
# Define the model
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
model.summary()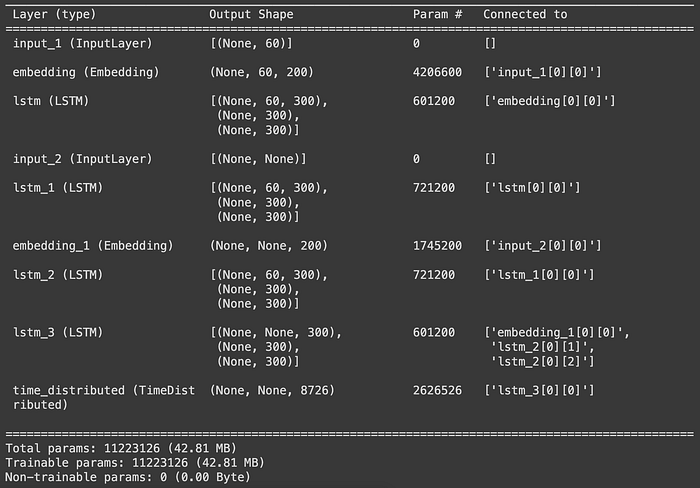
Explanation
1. We need only encoder_output1 as input to this encoder_lstm2 becuase we are building encoder decoder model and we need only hidden state as output from each time step. See the above diagram for more clarity.
2. In LSTM layer if we make return_state=False, then only encoder_output1 will come as output.
3. hidden_state and encoder_output are kind of same and cell state is different from both of them.
4. Trainable Parameters:
- For encoder embedding layers: 200(output of embedding layer to represent word) X 21033 (unique word size) so 200 X 21033
- For LSTM layer1: 4 X (input_dimension X units + units X units + units) i.e. 4 X (200x300+300x300+300).
- For LSTM layer2: 4x(input_dimxunits+unitsxunits+units) i.e. 4*(300x300+300x300+300).
- For decoder embedding layers: 200(output of embedding layer to represent word)x8726 (unique word size) so 200x8726.
- For LSTM decoder layer : 4 X(input_dim x units + units x units+units) i.e. 4 X (200 X 300 + 300 X 300 + 300) = 601200
- time_distributed : yvoc X output_from_decoder_lstm2 + yvoc i.e. 8726*300+8726
model.compile(optimizer='Adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model_name = "./model.h5"
save_model = tf.keras.callbacks.ModelCheckpoint(filepath=model_name,
save_weights_only=True,
save_best_only=True,
verbose=1)
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=10)
history = model.fit(
[x_tr, y_tr[:, :-1]],
y_tr.reshape(y_tr.shape[0], y_tr.shape[1], 1)[:, 1:],
epochs=70,
callbacks=[es, save_model],
batch_size=1024,
validation_data=([x_val, y_val[:, :-1]],
y_val.reshape(y_val.shape[0], y_val.shape[1], 1)[:, 1:]),
)
model.load_weights('./model.h5')Creating an inference (prediction) decoder model
# Inference Models
# Encode the input sequence to get the feature vector
encoder_model = Model(inputs=encoder_inputs, outputs=[encoder_outputs,
state_h, state_c])
# Decoder setup
# Below tensors will hold the states of the previous time step
decoder_state_input_h = Input(shape=(latent_dim, ))
decoder_state_input_c = Input(shape=(latent_dim, ))
decoder_hidden_state_input = Input(shape=(max_text_len, latent_dim))
# Get the embeddings of the decoder sequence
dec_emb2 = dec_emb_layer(decoder_inputs)
# To predict the next word in the sequence, set the initial states to the states from the previous time step
(decoder_outputs2, state_h2, state_c2) = decoder_lstm(dec_emb2,
initial_state=[decoder_state_input_h, decoder_state_input_c])
# A dense softmax layer to generate prob dist. over the target vocabulary
decoder_outputs2 = decoder_dense(decoder_outputs2)
# Final decoder model
decoder_model = Model([decoder_inputs] + [decoder_hidden_state_input,
decoder_state_input_h, decoder_state_input_c],
[decoder_outputs2] + [state_h2, state_c2])What is the need of decoder inference (prediction) architecture?
1. Training Process:
During training, the decoder model has access to the actual/true previous word in the sequence. This true word is used as the input for predicting the next word. This process, known as “teacher forcing,” allows the model to learn more efficiently by providing the correct context at each step.
2. Prediction (Inference) Process:
However, during prediction (inference), the decoder does not have access to the actual previous word. Instead, it uses the previously predicted word and the previous states (hidden and cell states) to predict the next word in the sequence. This is because, in a real-world scenario, the true sequence is not available.
This necessity to rely on its own predictions and states for generating the next word during inference/prediction is why we create a separate decoder inference architecture. The inference architecture is designed to iteratively generate each word of the output sequence, using the model’s own predictions as the input for subsequent steps.
Creating a decoder sequence
This function is used to generate a sequence (typically a summary or translation) from an input sequence using an encoder-decoder model with an LSTM architecture.
def decode_sequence(input_seq):
# Encode the input as state vectors.
(e_out, e_h, e_c) = encoder_model.predict(input_seq, verbose=0)
# Generate empty target sequence of length 1
target_seq = np.zeros((1, 1))
# Populate the first word of target sequence with the start word.
target_seq[0, 0] = target_word_index['sostok']
"""
The first element of target_seq is set to the integer index corresponding to
the start token (sostok), which signals the start of the target sequence.
"""
stop_condition = False
decoded_sentence = '' #initialized as an empty string to accumulate the decoded words.
while not stop_condition:
(output_tokens, h, c) = decoder_model.predict([target_seq]
+ [e_out, e_h, e_c], verbose=0)
# Sample a token
sampled_token_index = np.argmax(output_tokens[0, -1, :])
sampled_token = reverse_target_word_index[sampled_token_index]
if sampled_token != 'eostok':
decoded_sentence += ' ' + sampled_token
# Exit condition: either hit max length or find the stop word.
if sampled_token == 'eostok' or len(decoded_sentence.split()) \
>= max_summary_len - 1:
stop_condition = True
# Update the target sequence (of length 1)
target_seq = np.zeros((1, 1))
target_seq[0, 0] = sampled_token_index
# Update internal states
(e_h, e_c) = (h, c)
return decoded_sentenceExplanation
1. The encoder processes the input sequence to produce a context vector and initial states.
2. The decoder uses these states and the start token to generate the output sequence one token at a time.
3. The function loops until it generates an end token or reaches the maximum sequence length, updating the decoder’s input and states at each step.
Reverse encode the index to their tokens
reverse_source_word_index = x_tokenizer.index_word
reverse_target_word_index = y_tokenizer.index_word
target_word_index = y_tokenizer.word_index# To convert sequence to text
def seq2text(input_seq):
"""
This function converts a sequence of integers
(representing words) back into a human-readable
text format.
"""
newString = ''
for i in input_seq:
if i != 0:
newString = newString + reverse_source_word_index[i] + ' '
""""
It checks if the integer i != 0, which is
used to represent padding, so these are ignored.
"""
return newString
# To convert sequence to summary
def seq2summary(input_seq):
""""
This function converts a sequence of integers (representing words) into a
human-readable summary format. It specifically excludes special tokens used
to indicate the start and end of a sequence.
"""
newString = ''
for i in input_seq:
if (i != 0) and (i != target_word_index['sostok']) and (i != target_word_index['eostok']):
newString = newString + reverse_target_word_index[i] + ' '
return newStringExplanation:
1. For each valid integer i, it converts the integer back to its corresponding word using the reverse_source_word_index dictionary. This dictionary maps integers to their respective words in the source language.
2. The seq2text function converts a sequence of integers into the original text, ignoring padding 0.
3. The seq2summary function converts a sequence of integers into a summary, ignoring padding 0 and special start sostok and end eostok tokens.
4. Both functions utilize dictionaries reverse_source_word_index and reverse_target_word_index to map integers back to their corresponding words.
Prediction Summary
actual = []
predicted = []
for i in range(0, 50):
print ('Review:', seq2text(x_tr[i]))
actual.append(seq2summary(y_tr[i]))
print ('Original summary:', actual[-1])
predicted.append(decode_sequence(x_tr[i].reshape(1, config['max_text_len'])))
print ('Predicted summary:', predicted[-1])
print()
prediction_df = pd.DataFrame({'Actual':actual, 'Predicted':predicted})Output:
Review: a man has been caught taking videos of girls at the school arts festival organised in kerala s thrissur by cutting a hole into his slipper and fitting a phone camera in it the police who arrested the accused after noticing his suspicious movements said that he went through the crowds trying to take photos of women from below
Original summary: start kerala man caught taking videos on camera end
Predicted summary: start man arrested for raping woman in mumbai end
Review: the cbi on friday arrested the key accused in the 24 year old rss madras headquarters bomb blast from the outskirts of chennai the prime accused in the case mushtaq ahmed was absconding since the 1993 blast that claimed 11 lives ahmed had allegedly procured the explosive material for assembling the bomb and provided shelter to other accused persons
Original summary: start cbi arrests prime accused in rss madras headquarters blast end
Predicted summary: start kerala cm announces ã¢ââ¹5l for free in j k end
Review: actor anil kapoor has said that amitabh bachchan who took a five year long break after his 1992 film had advised him never to commit the mistake of taking a break from films anil said i went back and immediately signed two new films i have never taken a break in my 38 year long career
Original summary: start told me never to take a break from films anil end
Predicted summary: start i m not a star in my film on my burkha ekta kapoor end
Review: at least 40 militants were killed on saturday after a us air strike targeted an isis camp in afghanistan s nangarhar province the camp was used to train isis suicide bombers according to reports several weapons ammunition and explosives belonging to the terror group were also destroyed in the air strike officials said
Original summary: start 40 killed in us air strike on afghan isis training camp end
Predicted summary: start us navy kills self driving car in afghanistan end
Review: the trailer of upcoming psychological horror thriller film mother starring oscar winning actress jennifer lawrence has been released it will compete at this year s venice film festival the film has been directed by darren who is known for directing the oscar nominated movie black swan also starring javier and michelle mother will release on september 15
Original summary: start trailer of jennifer lawrence starrer mother released end
Predicted summary: start trailer of salman khan starrer released end
Review: have arrested a 23 year old btech student in uttar pradesh s noida for allegedly staging a robbery to steal ã¢ââ¹4 lakh belonging to his father to finance a gym the accused had claimed that while bringing money from his uncle in he was robbed by several men however police found out that he gave the money to his friend
Original summary: start student robbery steals dad s ã¢ââ¹4 lakh to open gym end
Predicted summary: start man arrested for raping minor girl in delhi end
Review: pakistan cricket board has sent a legal notice to bcci for not honouring a memorandum of understanding which had been signed between them in 2014 the mou stated that india and pakistan would play six bilateral series between 2015 and 2023 pcb is demanding compensation after claiming to have lost over 200 million due to india s refusal to play
Original summary: start pcb sends legal notice to bcci for not mou end
Predicted summary: start bcci to play county cricket s cricket team for ipl end
Review: addressing the maharashtra assembly cm devendra fadnavis said the government will ensure all demands made by agitating farmers under the forest rights act are addressed in a timely manner he added that loan waivers will be extended to farmers who could not avail the 2008 waiver scheme over 35 000 farmers marched around 180 km to press for their demands
Original summary: start maha cm promises time bound action on demands by farmers end
Predicted summary: start govt to give up to give up to sc st act against end
Review: mumbai police used a dialogue from the upcoming movie dhadak to send across a traffic advisory on twitter along with the screen capture of the movie s scene they also shared a caption that read don t underestimate the emotional quotient of traffic signals and their e challan is not too happy with your relationship
Original summary: start mumbai police use dhadak reference for traffic advisory end
Predicted summary: start man who stole 150 kg of heart attack on road safety end
Review: swiss tennis star and 20 time grand slam champion roger federer said that he will not get bored when he from the sport the 36 year old swiss star became the oldest world number one after winning the rotterdam open last week federer also added that he is actually looking forward to his retirement from tennis
Original summary: start won t get bored when i retire from tennis roger federer end
Predicted summary: start ronaldo scores goal in a day after being hit by 0 in end
Review: after resigning from the jammu and kashmir cabinet former bjp minister lal singh said he attended a rally supporting the kathua rape accused to voice residents demands of cbi inquiry in the case singh who was slammed for his presence at the rally organised by a hindu outfit in march said he resigned because of how it was being perceived
Original summary: start cbi probe in kathua case bjp minister who resigned end
Predicted summary: start bjp leader shot dead in jail for raping minor in mp end
Review: nasa has announced a 3 6 billion year old crater called crater as the landing site for its 2020 rover mission to mars getting samples from this unique area will how we think about mars and its ability to harbour life researchers said the crater was chosen after a five year search that examined some 60 other sites on mars
Original summary: start nasa announces landing site for its 2020 mars rover end
Predicted summary: start scientists develop ai to be made to be made end
Review: south african court has ruled that an art poster with the words f ck white people is not racist as it seeks to address problems caused by a white dominated society the poster is on display in the south african national gallery as part of the art of disruptions exhibition notably the artist behind the poster is a white man
Original summary: start f white people poster not racist south african court end
Predicted summary: start twitter reacts to tweet on twitter account end
Review: s captain faf du plessis has been suspended from playing in the third south africa pakistan test for maintaining a slow over rate during south africa s nine wicket win in the second test on sunday du plessis was also fined 20 per cent of his match fee while his teammates were fined 10 per cent of their match fees
Original summary: start sa captain du suspended from third test vs pak end
Predicted summary: start india s 1st test team to be a test runs in ipl 2018 end
Review: tuesday announced its plans to purchase 50 atr turbo planes worth over 1 3 billion indigo will become the third indian carrier after air india and jet airways to induct the 68 78 seater atr planes in its fleet indigo is expected to be a part of the government s regional air connectivity scheme udan by inducting the atr planes
Original summary: start indigo to buy 50 planes for 1 3 billion end
Predicted summary: start us startup raises 1 million end
Review: gurugram police on wednesday arrested a policeman and a jail convict for allegedly getting a gangster to make a threatening phone call on june 27 from bhondsi jail a police official said that the inmate sought help of the gangster to threaten his rival over a property dispute and a policeman was involved in making this happen
Original summary: start gangster makes threat call from jail two arrested end
Predicted summary: start woman kills self after being hit by a year old girl endCalculating the accuracy of the model
Unlike other machine learning models such as Artificial Neural Networks (ANN), Convolutional Neural Networks (CNN), and algorithms like Logistic Regression, Gradient Boosted Decision Trees (GBDT), and Random Forest Classifier, in Natural Language Processing (NLP) tasks such as text summarisation, we often use the ROUGE score to evaluate the performance of the model.
What is Rouge Score?
ROUGE, or Recall-Oriented Understudy for Gisting Evaluation, is a set of metrics and a software package used for evaluating automatic summarisation and machine translation in NLP. Range of Rouge score lies between 0 and 1.
It is basically precison, recall and f1_score for the classification problem. Instead of using accuracy score for normal ML/CNN problem we use Rouge Score for text summarization and machine translation tasks.
r_score = []
rouge_pr = []
rouge_rc = []
rouge_f = []
scorer = rouge_scorer.RougeScorer(['rouge1', 'rougeL'], use_stemmer=True)
for indx, data in prediction_df.iterrows():
r_score = scorer.score(data.Actual, data.Predicted)
pr = list(r_score['rouge1'])[0]
rc = list(r_score['rouge1'])[1]
fmeas = list(r_score['rouge1'])[2]
rouge_pr.append(pr)
rouge_rc.append(rc)
rouge_f.append(fmeas)
prediction_df['rouge_pr'] = rouge_pr
prediction_df['rouge_rc'] = rouge_rc
prediction_df['rouge_f'] = rouge_f Actual Predicted rouge_pr rouge_rc rouge_f
0 start deepika denies starring as amrita in bha... start deepika to play in biopic on padmavati ... 0.363636 0.363636 0.363636
1 start shahid t
akes care of ishaan me on being ... start my son taimur is a dream to be a on my ... 0.285714 0.333333 0.307692
2 start pilot dies on board airways plane mid ai... start pilot flyers to fly plane with emergenc... 0.400000 0.400000 0.400000
3 start celebrations begin at ram nath kovind s ... start pm modi to be called by a dictator in u... 0.166667 0.200000 0.181818
4 start guest their heads in protest in mp end start women wear skirts in protest against end 0.500000 0.444444 0.470588
5 start can t tolerate weinstein like behaviour ... start i don t know how to be used to stop fac... 0.266667 0.400000 0.320000
6 start gujarat poll panel orders probe in contr... start ec orders removal of using fake news on... 0.250000 0.272727 0.260870
7 start facebook suspends canadian firm amid dat... start facebook suspends facebook over fake ne... 0.600000 0.600000 0.600000
8 start iraq s first non arab president passes a... start iraq s 1st state citizen to be held in ... 0.333333 0.400000 0.363636
9 start us scientists propose new organ in human... start scientists propose new type of human sy... 0.666667 0.600000 0.631579Scope of Improvement
As we can see through the score that the model is not giving a proper summary, therefore we need to use different model for the text summarisation.
1. Trying with different hyper-parameters like Learning rate, different optimisers, regularisation techniques, changing no of units/neurons, etc
2. Stack more layers of LSTM in encoder and decoder layer
3. If the model is overfitting then stacking 5–10 layers in encoder and decoder layer then trying using GRUs. Since GRUs have lesser no of trainable parameters it can prevent overfitting.
3. Trying some complex methods like adding attention layers or use transformer based architecture like Bert. Currently, transformers/ BERT are state of the art model and are majorly use in most of the models.
