MultiPDF Reader using RAG
In this blog we will going to learn how one can implement a GenAI project just by reading the documentation provided in this blog.

Basic understanding of the project:
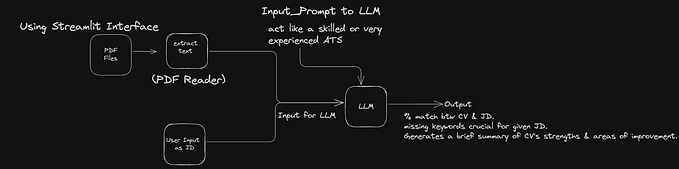
This project is a MultiPDF Reader using RAG (Retrieval-Augmented Generation), designed to take multiple PDF files as input and generate outputs using the latest information from the provided PDFs and the OpenAI LLM model. The interface is built with Streamlit, providing an easy-to-use web interface for users to upload PDFs and get responses based on the content.

Installation
Clone the repository:
git clone "Your Github repo link"Create a virtual environment and activate it:
python3 -m venv venv
source venv/bin/activateInstall the required dependencies
pip install -r requirements.txtstreamlit
python-dotenv
langchain
PyPDF2
faiss-cpu
langchain-community
langchain
openai
langchain-openaiSet up environment variables by creating a .env file with the necessary keys (e.g., OpenAI API key).
Importing all the dependencies
import os
import streamlit
from dotenv import load_dotenv
from PyPDF2 import PdfReader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.models import ChatOpenAI
from langchain.prompts import PromptTemplate
from langchain.chains.question_answering import load_qa_chainos : It provides a way of interacting with the operating system. It is used to access environment variables, specifically to get and set the OpenAI API key (os.getenv and os.environ).
load_dotenv : It reads key-value pairs from a .env file and adds them to the environment variables. load_dotenv() is used to load the OpenAI API key from the .env file so it can be used securely without hardcoding it into the script.
streamlit : It is used to create the user interface, handle file uploads, and capture user input for questions. It serves as the front-end for your RAG project.
PdfReader : It is used to extract text from uploaded PDF files. This is the first step in processing the documents for your RAG pipeline.
RecursiveCharacterTextSplitter : used to split large blocks of text into smaller, manageable chunks based on character count. This ensures that the text is divided in a way that doesn’t split important context, making it ideal for embedding generation and retrieval.
OpenAIEmbeddings : OpenAIEmbedding generates vector embeddings for text using OpenAI’s models. These embeddings are essential for converting text into a numerical format that can be stored in a vector database for similarity search.
FAISS : used to store and retrieve vector embeddings generated from the text chunks. This allows you to quickly search and find relevant text chunks based on the user’s query.
ChatOpenAI : We are using OpenAI as the large language model. It provides an interface to interact with OpenAI’s chat-based language models which serves as the backend language model for generating responses to user queries.
PromptTemplate : Initial prompt that we as user give to the OpenAI model so that it can act accordingly. It provides tools to create templates for prompts that can be used with language models and allows you to define a structured template for the prompt that is passed to the LLM. This helps control how questions are framed and how the context is presented to the model.
load_qa_chain : The class will make chain of prompt Template, user question and OpenAI LLM. It creates a chain that can handle question answering tasks by taking the LLM, a prompt, user question and the context documents retrieved from the vector store. It orchestrates the interaction between these components to generate an answer.
Setting Up Environment Variables for API Configuration
load_dotenv()loads the environment variables from a.envfile.os.getenv("OPENAI_API_KEY")retrieves the API key from the environment.os.environ['OPENAI_API_KEY']sets the API key in the current session's environment variables, making it available to any code or library that needs it.
#load environment variable
load_dotenv()
openai_api_key = os.getenv("OPENAI_API_KEY")
#Configure it with OPENAI API key
os.environ['OPENAI_API_KEY'] = openai_api_keyReading and Processing PDF Files
The first major function within our application is designed to read PDF files:
- PDF Reader: When a user uploads one or more PDF files, the application reads each page of these documents and extracts the text, merging it into a single continuous string.
Once the text is extracted, it is split into manageable chunks:
- Text Splitter: Using the Langchain library, the text is divided into chunks of 1000 characters each. This segmentation helps in processing and analyzing the text more efficiently.
# extract all the text from multiple PDFs document
def get_pdf_text(pdfs_docs):
text = ""
for doc in pdfs_docs:
reader = PdfReader(doc)
for content in reader.pages:
text+=content.extract_text()
return text
# splitting into small manageable chunks
def split_into_chunks(text):
text_split = RecursiveCharacterTextSplitter(chunks_size = 10000, chunks_overlap = 1000)
text_chunks = text_split.text_split(text)
return text_chunks
Creating embedding for text chunks
This function converts the text chunks into vector representations using OpenAIEmbeddings.
After that it uses FAISS vector database to store these vector embeddings.
def text_into_embedding(text_chunks):
# Initalizing OpenAI Embeddings
embeddings = OpenAIEmbeddings(open_api_key = open_api_key)
# Initalizing FAISS vector store database
vector_store = FAISS.from_texts(text = text_chunks, embeddings = embeddings)
# Saving the vector embedding into the local system with file name as FAISS.index
vector_store.save_local("faiss_index")Building the Conversational AI
The core of this application is the conversational AI, which uses OpenAI’s powerful models:
- AI Configuration: The app sets up a conversational AI using OpenAI’s GPT model. This AI is designed to answer questions based on the PDF content it has processed.
- Conversation Chain: The AI uses a set of prompts to understand the context and provide accurate responses to user queries. If the answer to a question isn’t available in the text, the AI is programmed to respond with “answer is not available in the context,” ensuring that users do not receive incorrect information.
def get_conversation_chain():
prompt_template = """
Answer the questions as detailed as possible from the provided context. Make sure to provide all the details.
If the answer is not in the provided context, just say, "The answer is not available in the context". Do not
provide a wrong answer.\n\n
Content:\n {content}?\n
Question:\n {question}?\n
Answer:
"""
llm = ChatOpenAI(model = 'model-4o-mini', temperature = 0.7, api_key = open_api_key)
prompt = PromptTemplate(template = prompt_template, input_variables = ['content', 'question'])
chain = load_qa_chain(llm = llm, prompt = prompt, chain = 'stuff')
return chainRetrieving and Answering User Queries from PDF Document Context
The user_input() function takes a user query, searches the vector store for relevant document chunks, and then uses a language model to generate a context-aware answer. The result is displayed to the user via the Streamlit interface.
- Key Operations:
- Loads the FAISS vector store.
- Performs a similarity search with the user’s question.
- Uses a conversational chain to generate an answer.
- Displays the answer in the app.
def user_input(user_question):
embeddings = OpenAIEmbeddings(open_api_key = open_api_key)
# load the vector store database
# allow dangerous deserialization, but only do this if you trust the source of the file
db = FAISS.load_local("faiss_index", embeddings = embeddings, allow_dangerous_deserialization=True)
docs = db.similarity_search(user_question)
chain = get_conversation_chain()
response = chain(
{"input_documents": docs, "question": user_question},
return_only_outputs=True
)
st.write("Reply: ", response['output_text'])Implementing the User Interface
With the backend ready, the application uses Streamlit to create a user-friendly interface:
- User Interface: Users are presented with a simple text input where they can type their questions related to the PDF content. The application then displays the AI’s responses directly on the web page.
- File Uploader and Processing: Users can upload new PDF files anytime. The application processes these files on the fly, updating the database with new text for the AI to search.
def main():
st.page_config("Chat with PDF")
st.header("RAG based Chat with PDF")
user_input = st.text_input("Write your Question")
if user_input:
user_input(user_question)
with st.sidebar():
pdf_doc = st.file_uploader("Upload your PDF Files and Click on the Submit & Process Button", accept_multiple_files=True)
if st.button("Submit & Process"):
with st.spinner("Processing : "):
raw_text = get_pdf_text(pdf_doc)
text_chunks = split_into_chunks(raw_text)
vector_store(text_chunks)
st.success("Done")
if __name__ == "__main__":
main()
Conclusion
By following this guide, you can build a robust Multi PDF RAG Chatbot that reads, processes and interacts with PDF data seamlessly. This application leverages powerful tools like Streamlit, Langchain, FAISS, and OpenAI’s GPT model to provide a comprehensive solution for managing and querying PDF content through conversational AI.
For more info visit my GitHub repo at :
https://github.com/sambhavm22/PDF-Reader