Emotion Detection Model
Problem Statement:
The goal is to create a deep learning model that can accurately categorise human emotions, when a image or a video is being provided. These predefined emotion categories, are happiness, sad, angry, fear, surprise, neutral, and disgust. The model can be used for a variety of purposes, including sentiment analysis, human-computer interaction, and the provision of emotional context for user-generated content.
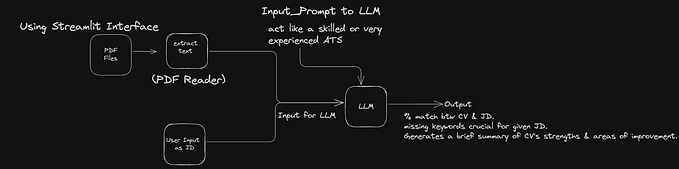
Solution Workflow Diagram

Challenges face
i) Challenges in this dataset: -
The following are the main ideas taken from the text that was provided:
1. Low-quality photographs: The 48x48 size of the photographs may make it more difficult for the model to recognize them correctly.
2. Grayscale Pictures: Since the photos are grayscale, they lack color information, which might give more context and distinguishing characteristics to the classification.
3. Insufficient Color Details: The model’s performance may be impacted by the grayscale photos’ limited feature set compared to color images.
4. Influence of Age: The participants’ ages have an impact on how accurately complex emotions are recognized.
ii) Challenges in real world application
1. Focus on Face: In real-world scenarios, generally extracted images do not majorly focus on face. Therefore, in order to make a good emotion detection model, we need images that are primarily focused on the face.
2. Need for Cropping: In real-world scenarios, images need to be cropped to focus on the face before training a model.
3. Inconsistent Image Sizes: The images in the dataset have different sizes.
4. Standardizing Image Sizes: Before training any model, all images need to be resized to the same dimensions.
Usage:
The capacity to recognize non-verbal cues, such as facial expressions, is essential for understanding others’ feelings and intentions. Such models can decrease the need for human interaction and thus increase efficiency during, for example, border checks in airports. FRT can even be employed in medicine, such as in identifying subtle facial traits to determine genetic disorders. A large number of tech companies are developing facial biometric systems.
YouTube is soon introducing a feature that lets it recommend video to you based on your facial expression when you allow the app to access your phone’s camera.
Detailed Dataset Description:
Kaggle — https://www.kaggle.com/datasets/msambare/fer2013
The data consists of 48x48 pixel grayscale images of faces. The faces have been automatically registered so that the face is more or less centred and occupies about the same amount of space in each image.
The task is to categorize each face based on the emotion shown in the facial expression into one of seven categories (0=Angry, 1=Disgust, 2=Fear, 3=Happy, 4=Sad, 5=Surprise, 6=Neutral)
In this dataset, we have two directories: the train directory and the test directory. Each directory contain 6 other directories, which indicate 6 different class names. (i.e 0=Angry, 1=Disgust, 2=Fear, 3=Happy, 4=Sad, 5=Surprise, 6=Neutral)
Image Distribution in train and test dataset:

In the train directory, it can be observed that the data is unevenly distributed. Disgust expression facial images contribute only 1.5% to the overall images whereas happy emotion contribute to mostly 1/4th of the total images

In test directory, it can also be observed that the data is unevenly distributed. Disgust expression facial images contribute only 1.5% to the overall images whereas happy emotion contribute to mostly 1/4th of the total images
Since, the data distribution in each class is imbalanced, it is recommended to apply class weights according to the number of images in each category.
Image Size details for each classes:

Randomly displaying images along with image size from train directory to check if all the images are of same size.

Randomly displaying images along with image size from train directory to check if all the images are of same size.
Displaying Random images from each category:

Data cleaning and data analysis are done!!! Now we can train our model.
Model Building:
We are building 4 CNN models:
1. CNN Model from Scratch
2. CNN model with Image Augmentation
3. CNN model using Transfer Learning (VGG16)
4. CNN model using Transfer Learning (ResNet50)
whichever model is performing best, we can pick that model and do predictions on test data using that model.
1. CNN Model from Scratch
CNN Model from Scratch Model Summary:

There are 17,046,535 total parameters in the CNN model, out of which 17,044,871 are trainable and 1664 are non-trainable parameters.

Confusion Matrix:

It can be observed that for the disgust category the model is unable to predict any of the images. Besides the model is not that accurate in predicting actual classes for a given image.

These are some of the images from the test data. Clearly, it is seen that the model is making errors in predicting the actual true class for a given image. Therefore, we can conclude that the model is not suitable for us in predicting class.
2. CNN Model with Image Augmentation
What is image augmentation?
Image augmentation is a technique used in computer vision and image processing to artificially expand the size of an image dataset by applying various transformations to the images in the dataset. This process helps to increase the variability and diversity of the data, which can lead to improved performance of deep learning models, particularly in tasks such as image classification, object detection, and image segmentation.
CNN Model with Image Augmentation Model Summary:
There are 17,046,535 total parameters in the CNN model, out of which 17,044,871 are trainable and 1664 are non-trainable parameters. Same no of parameters are above, however, no of images increases due to image augmentation.


As compare to previous model that is (CNN model from Scratch) the performance of the model increase, as loss decreases. Previously, the model accuracy wad 55%. Now, with image augmentation the model accuracy increases by 4% i.e. 59%.
Confusion Matrix

Here also for the disgust category the model is unable to predict any of the images. Therefore we cannot rely on this model.
3. CNN Model with Transfer learning (VGG16)
What is transfer learning?
The process of applying knowledge acquired from training a model on one task to another that is related to it is called transfer learning. The concept is to use a pre-trained model as a foundation for a new model that performs a different task or functions in a different domain. The pre-trained model has already been trained on a big dataset and has learnt broad patterns or features.

VGG16 consists of 16 layers, including convolutional layers, max pooling layers, and fully connected layers
i) Convolutional Layers: A ReLU (rectified linear unit) activation function comes after each convolutional layer in the network’s initial architecture. The convolutional layers of the network are equipped with small 3x3 kernels that have a stride of 1 and a padding of 1, which allow the network to preserve the input’s spatial dimensions.
ii) Max Pooling Layers: These layers minimize the spatial dimensions of the feature maps and come after a few convolutional layers. They have a 2x2 kernel and a stride of 2.
iii) Fully Connected Layers: The network moves to three fully connected layers after a sequence of convolutional and max pooling layers. There are 4096 neurons in each of the first two fully linked layers, and the number of neurons in the final layer is the same as the number of classes in the classification task. Mostly these fully connected layers are customize as per the requirements of the problem.
iv) Softmax Output: The last layer outputs the probability for each class using a softmax activation function.
During the train, first of all, we need to change the size of the image from (48,48,1) to (224,224,3) in order to train the model, since these pre-trained model accept images in (224,224,3) format.
To train VGG16 for custom data, we are replacing last 3 layers from the original VGG16 model. Instead, we will build our own layers based on our custom requirements.
VGG16 Model Summary:

There are 40,934,215 parameters, out of which 30,939,143 are trainable parameters and 9,995,072 are non-trainable parameters.

Confusion Matrix of VGG16 Model

Here, the model is able to make some correct predictions for the disgust category. However, there is still a lot of improvement that needs to be done in order to consider it as a final model.
4. CNN Model with ResNet50

Convolutional layers, residual blocks, max pooling layers, and fully linked layers make up ResNet50’s 50 layers. This is how the architecture is broken down:
i) Residual Blocks: Often referred to as shortcuts or skip connections, residual blocks are the main component of ResNet architecture. These blocks are made up of several convolutional layers connected by a shortcut link that skips a layer or layers. The network can learn residual functions thanks to the shortcut connection, which adds the block’s input to its output.
ii) Convolutional Layers: A max pooling layer comes after the network’s convolutional layer. Subsequently, the network consists of many residual blocks, with convolutional layers using 3x3 filters and ReLU activation functions in each.
iii) Max Pooling Layers: Feature maps’ spatial dimensions are occasionally reduced and their abstraction level is raised by using max pooling layers.
iv) Global Average Pooling: The network employs global average pooling to decrease the feature map size to a single value per channel following the sequence of residual blocks.
v) Fully Connected Layer: There are as many neurons in the last fully connected layer as there are classes in the classification task.
vi) Softmax Output: The last layer outputs the probability for each class using a soft max activation function.
During the train, first of all, we need to change the size of the image from (48, 48, 1) to (224, 224, 3) in order to train the model, since these pre-trained model only accept images in
(224, 224, 3) format.
To train ResNet50 for custom data, we are removing last 50 layers from the original ResNet50 model. Instead, we will build our own layers based upon our requirements.
ResNet50 Model Summary:

In total, there are 29,996,295 parameters, out of which 22,779,527 are trainable parameters and 7,216,768 are non-trainable parameters in this ResNet50 model.


Confusion Matrix with ResNet50 Model

Here, the model is able to make most of the actual prediction for the disgust category as well as for other classes. We can consider this as our final model.
AUC ROC plot for each class

For happy, surprise and disgust classes, the ResNet50 model is able to predict with more than 80% accuracy. For the remaining classes, the model is able to predict with decent accuracy.
This is one of the many ways one can approach a computer vision problem. However, in real world scenarios, organisations use the transfer learning method to train CNN models, as the institutes do not have enough computational power to train a model from scratch. Besides, funds also play a crucial role in training a model from scratch.